
今回も画像生成AIに関する話題で、タイトルの通り
を丁寧にご紹介するという内容になっています。
画像生成AIを使ってイラストを生成する際、ポーズや構図を決めるときは
という方法が主流です。この方法ではかなりザックリしたポーズ・構図を指定することはできるものの、単語で指定することもあって思い通りのポーズを完全再現したイラストを生成するのはかなり困難でした。
ところが、つい先日その問題を解決する「ControlNet」と呼ばれる新技術が公開されて大変話題になりました。しかも速攻でStable Diffusion web UI用の無料の拡張機能も開発されて、誰でも簡単に使えるようになったとのことだったのでさっそく試してみることにしました。
ここではこのControlNetの使い方について解説していきますね。
新しいバージョンのControlNet 1.1が発表されました!これに伴って新機能が色々追加されたので記事のアップデートを行いました。
※2023/09/05追記:
ControlNet拡張機能がv1.1.400にて最新のStable Diffusion XLに対応したので新しい記事を書きました。

下記の内容は旧Stable Diffusion v1.5用のものなので少々古い情報になりますが、基本的な使い方は最新版と同じです。
ControlNetを使ったポーズ指定の例
まずはじめに、私が実際にControlNetを使ってポーズを指定した美少女イラストをご覧頂こうと思います。
ControlNetでは下のような元画像を用意して呪文を唱えると…

画像提供:ぱくたそ 様
https://www.pakutaso.com/
下のようにほぼ同じポーズのイラストが生成されます。


ControlNetのすごいところはポーズや構図がかなり厳密に再現される点です。つまり欲しいポーズのイラストが決め打ちで出てくるので、今までのように何度もガチャを引く必要はありません。
ポーズ指定以外の活用例
ちなみに上記では一番分かりやすいポーズ指定を例に挙げていますが、ControlNetを使えば他にも
- 線画だけのイラストを着色する
 →
→ 
- キャラクターの特徴を維持したまま色や画風だけ変える
→ 
- 落書きからリアルな画像を作る
→ 




などなど色々なことに活用できるのでとても汎用性が高い技術となっています。
Stable Diffusion web UIへのインストール方法
次にControlNetはStable Diffusion web UIに拡張機能をインストールすれば簡単に使うことができるので、その方法をご説明します。
拡張機能のインストール
まずは拡張機能をインストールします。やり方は簡単で「拡張機能」タブ→「拡張機能リスト」と進み、読込ボタンを押して拡張機能の一覧を出し、「sd-webui-controlnet」を探して右側のインストールボタンを押すだけです。

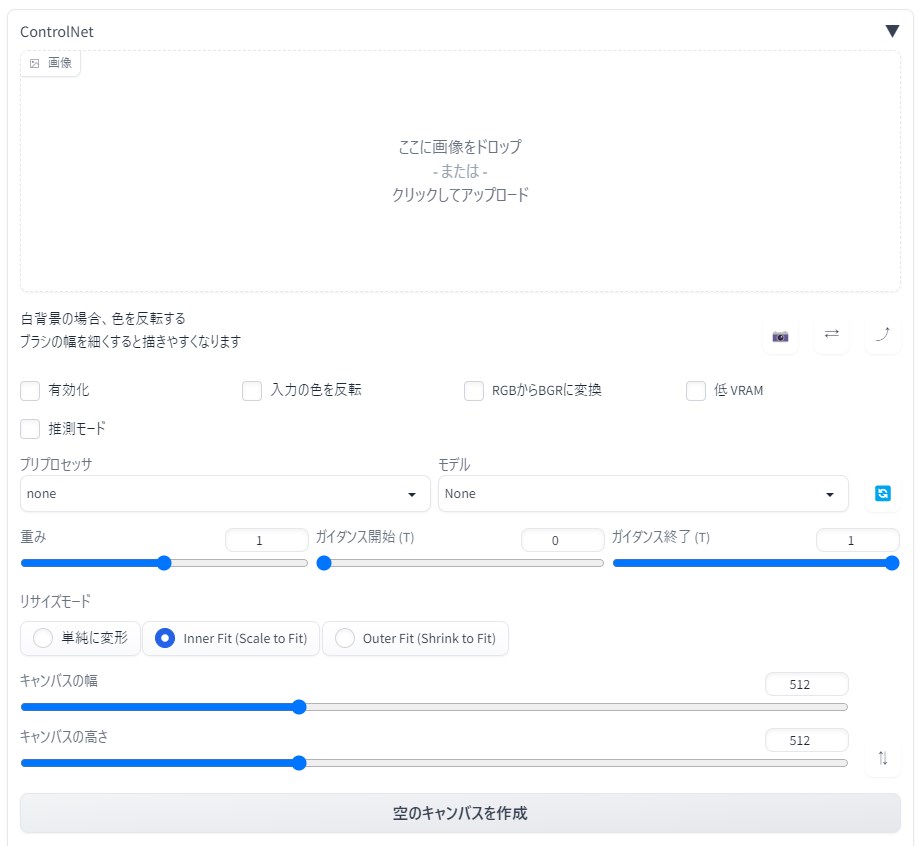
あとはweb UIを再読み込みすれば、txt2img・img2img画面の左下にControlNetの設定欄が出現します。
必要なControlNetモデルのダウンロード
次にControlNetを使うには専用のモデルファイルが必要です。そこで下記ページから使うものを選んでダウンロードします。

一応上記が公式ファイルですが、精度を落として容量を削減した軽量版もあります。どちらを使うかはお好みで。
ControlNet 1.1にはモデルが全部で14種類も用意されており(※v1.0のときは8種類でした)、それぞれ使用するアルゴリズムが異なります。超ざっくり説明すると下記のとおりなので好きなものを選んでください。
- ip2p:プロンプトで画像を修正する「Instruct Pix2Pix」を使うモデル。
- shuffle:画像をシャッフルし、再構成することで画像を生成するモデル。
- depth:深度情報を元に画像を生成するモデル。
- canny:画像の輪郭を抽出してそれを元に画像を生成するモデル。シンプルで分かりやすいのが特徴。
- inpaint:画像の一部を修正する「Inpainting」を使うモデル。
- lineart:線画を作成し、それを元に画像を生成するモデル。
- lineart_anime:上記のlineartモデルのイラスト向け版。
- mlsd:直線的な線を抽出して画像を生成するモデル。建物や部屋など構造物の画像を生成するときに便利。
- normalbae:法線マップ(ノーマルマップ)を使って画像を生成するモデル。
- openpose:人物のポーズを検出し、それをもとに棒人間を生成してポーズを制御するモデル。
- scribble:落書きからリアルな画像を生成できるモデル。
- seg:「セマンティックセグメンテーション」という手法を使うモデル。
- softedge:ソフトな輪郭を使って画像を生成するモデル。ディテールを維持するのが得意で、色変更等に活用するとよい。
- tile:高解像度の画像を生成するためのモデル。
各モデルについての詳しい紹介記事もあります。ご興味があればそちらも併せてご覧ください。

「モデルを全部ダウンロードするのはダルいなぁ…」という方には、
- シンプルで分かりやすいcannyモデル
- 棒人間でポーズを指定できるopenposeモデル
- イラスト制作に便利なlineart_animeモデル
- 落書きを清書できるscribbleモデル
あたりが特にオススメです。ダウンロードできたらモデルファイルを下記フォルダに移動させてください。
これでインストール作業は完了です。
ControlNetの基本的な使い方
さて前置きが長くなってしまいましたがこの辺でControlNetの基本的な使い方についてご説明します。ただし使用する選択したモデルによって設定項目が多少違うので、ここでは先ほどおすすめしたcannyモデルの場合についてご説明します。
主な手順は次のとおりです。
- 必要な設定を行う
- 入力画像を指定する
- いつも通り呪文を入力して生成ボタンを押す
手順1:必要な設定を行う
まずは必要な設定を行います。ControlNetの設定欄を展開し、次の画像のように設定を行ってください。

- 「有効化」にチェックを入れる
- プリプロセッサを選択する(ここでは例としてcannyを選択)
- プリプロセッサに対応したモデルを選択する
プリプロセッサ欄には、モデルが入力画像を活用しやすくするための「前処理」を行う手法を選択します。モデルに合ったものを選ばないと画像生成がうまく行われないので注意してください。
なお一つのモデルに対応するプリプロセッサが複数ある場合もあって「どれを使えばいいんだろう?」と迷ってしまうかもしれません。ControlNet 1.1のプリプロセッサについては下記の記事で詳しく比較を行っていますので、そちらも併せてご覧頂ければと思います。

手順2:入力画像を指定する
お次はポーズの元となる画像を指定します。指定方法は「ここに画像をドロップ」と書かれた部分に任意の画像をドラッグ&ドロップするだけです。ここでは次の画像をお借りして入力画像としました。

画像提供:ぱくたそ 様
https://www.pakutaso.com/
手順3:呪文を入力して生成ボタンを押す
あとは通常通り呪文を入力して生成ボタンを押せばOKです。下のようなプロンプトを入力すると…
次のようなイラストが生成されました。

キャラクターが元画像と同じポーズをとっているのが分かります。
応用編:ControlNet活用術
では最後にControlNetの応用的な使い方の一例をご紹介します。参考にしていただければ幸いですが、下記以外にも様々な活用方法があるのでぜひご自身でも研究してみてください。
- 棒人間を弄ってポーズを指定する
- 適当に描いた線画を清書→色塗り
- 複数のControlNetを同時に適用する
応用例1:棒人間を弄ってポーズを指定する

まずはControlNetの「Openpose」モデル用の棒人間画像を作れる拡張機能をインストールし、それを使ってポーズを思い通りに指定する方法があります。Openposeモデルでは本来は
という手順を踏むのですが、棒人間を自分で用意してしまえばわざわざ入力画像を用意しなくても済むというわけです。自動生成と比べると手間はかかるものの細かい調整ができるので、こっちのほうが便利だと思う人も多いようですね。
応用例2:適当に描いた線画を清書→色塗り

次に適当に描いた線画をControlNetで清書→さらに色塗りを行うという方法もあります。この方法を使えば、絵があまり上手くなくてもハイクオリティなイラストに仕上げることができるのでイラスト制作がとても捗ります。
ちなみにこの方法では線画を一旦清書する手順を踏むのがポイントです。適当に描いた線画に直接色を塗るよりも品質が向上します。
応用例3:複数のControlNetを同時に適用する

あとは複数のControlNetを同時に適用することもできます(=Multi ControlNet)。例えば上記の記事でご紹介しているやり方のように
- openpose
- depth
を2つ同時に適用して体だけでなく手や指まで正確に制御することも可能です(※ただしControlNet 1.1では、openposeに指まで制御できる機能がついているので上記のようなやり方をする必要性は薄まりました)。このように複数のControlNetを組み合わせることで色々と便利で面白いことができます。
おわりに
以上、ControlNetの使い方を一通りご説明しました。これがあればポーズ指定で何度も試行錯誤をしなくても済み、とても便利なのでぜひ皆さんも試してみてください。
この記事が何かしらお役に立てば幸いです。

