
今回は画像生成AIに関する中級者向けの話題で
を一通りご紹介するという内容になっています。
Stable Diffusion系のモデルを使って画像を生成していると、
- 特定のキャラクターのイラストを出したい
- あるアニメの絵柄を再現したい
といった欲求が出てくることがあります。ただ画像生成AIはそのままだと「特定の絵柄・キャラクターを決め打ちで出す」のは非常に難しいですし、それを解決する手法もありましたが高性能なPCが必要で時間もかかる…という問題がありました。
しかしそのような問題を解決する「LoRA」という手法が知られて、今ではかなりポピュラーなやり方になっています。ここではこのLoRAについて
- LoRAの概要
- 環境の構築方法
- LoRAを使った学習のやり方
- 「Stable Diffusion web UI」でLoRAモデルを使う方法
といった点を一通り丁寧に解説していきますね。
LoRAは便利ですが強力な手法なので悪用しないようにしてください。
※追記:
Stable Diffusion XLや最新のFLUX.1をベースにした学習のやり方記事を書きました。もしご興味があればそちらも併せてご覧ください。


※以下、詳しく解説しすぎてとんでもない長文になっております…。
LoRAとは?
まずはじめに
- LoRAって何だよ…
- 調べてみたけど結局何なのかよく分からん!
と思っている方もいらっしゃるかと思いますので、概要を簡単にご説明していこうと思います(※とはいえ私も専門家ではないので、概念については誤解を招く説明になってしまうかもしれない点はご容赦ください)。
LoRAは「Low-Rank Adaptation」の略語で、端的に言えば
です。ただこれだけだと何が何だかよく分からないので具体例を出しましょう。
例えば、Stable Diffusion系のモデルを使って「特定のキャラクターのイラスト」を生成する場合を考えてみます。このとき普通は
必要がありますよね。でもこの方法には
- モデルの学習元に含まれていないようなマイナーなキャラクターだと、どんなに良くても「そっくりさん」レベルのイラストしか出ない
- 有名キャラであってもなんか違うキャラクターになってしまう場合がある
- 目当ての画像が生成されるまで何度もガチャを引き続ける必要がある
といった問題点があります。なのでもしできるなら目当てのキャラクターが決め打ちで出てきて欲しいものです。
そこでこの問題を解決するために
のが追加学習です。とりあえず、LoRAはこの追加学習の手法の一種だと思っていただければOKだと思います。
LoRAの例
では実際に私がLoRAを試した結果を掲載しておきます。
【条件】
- 教師データ:私のオリジナルキャラクター「くろくまちゃん」のイラスト15枚
- 使用モデル:Stable Diffusion v1.5
- エポック数:10
教師データは下の画像のような感じです。

これを使って学習を行い、出来上がったLoRAモデルを使って自動生成した画像は下のとおりです。



元のキャラクターにかなり近い画像が生成されました!かわいい。
このようにLoRAを使うと、目当てのキャラクター・絵柄のイラストを決め打ちで生成できるようになるのでとても便利です。
別の追加学習法(DreamBooth等)との違い
さて追加学習というとLoRAだけでなく「DreamBooth」など別の手法もあるのですが、それと比較するとLoRAの強みは
- 他の手法よりもずっと短時間で学習させることができる
- 比較的低スペックなPCでも学習処理を行うことが可能
- 学習結果のモデルファイルが軽量
といった点にあります。特に短時間で学習できる点とスペックが低めのPCでも処理を行える点は強く、執筆時点では最もポピュラーな手法となっているようです。
必要なPCスペック・必要なデータ
次はLoRAを使った学習処理に必要なPCスペックやデータについてです。
必要なPCスペック(主にグラボが重要)
まず必要なPCスペックは次のとおりです。
つまり画像生成を行うときと同様にグラフィックボードの性能が非常に重要です。なのでもし性能が足りないようでしたら買い替えを検討することをお勧めします。
ちなみにおすすめのグラフィックボードについては下記の記事でご紹介していますので、ご興味があればそちらも参考になさってください。

学習に必要なデータについて
次に学習には教師となるデータが必要なのでそれについてご説明します。実はLoRAを使った学習方法には主に次の2通りのやり方があります。
- DreamBooth方式:
教師データと正則化画像を使って学習させるやり方 - ファインチューン方式:
教師データとキャプションファイルを使って学習させるやり方
どちらでも好きな方法を使っていただいてOKなのですが、この記事では1番目のDreamBooth方式で学習を行うものとします。この場合学習には次の2種類のデータが必要です。
- 教師データとなる画像
- 正則化画像
教師データ
まずは教師データです。下記の要件を満たした画像が最低20枚以上必要になります。
- 学習させたい被写体が単体で映っている
- 画像ごとに色々なポーズをとっている
- 画像ごとに色々な背景が映っている
あまりにも似たポーズや似た背景ばかりの画像を学習させるとそれを強く覚えてしまうので注意してください。また、当然ですが教師データは少ないよりは多いほうがいいです。質・量の両方を考慮して集めましょう。
正則化画像
それからもう一つ必要となるのが正則化画像です。学習対象や用途にもよりますが、一般的に学習ではこの正則化画像が大量に必要です(※作り方は後述します)。
正則化画像とは簡単に言うと
のことです。…といってもこの説明だと意味不明だと思うのでもう少し説明します。
「インスタンスプロンプト」と「クラスプロンプト」
まず、画像生成でLoRAでの学習結果を反映させる際には「インスタンスプロンプト」と呼ばれるプロンプトを呪文に含める必要があります。インスタンスプロンプトは学習させた絵柄を呼び出し、生成される画像に反映させる役割を持ちます。
インスタンスプロンプトには例えば下記のようにモデルに関連付けられていないキーワードを割り当てるのがよいとされています(※下記以外でも無意味なキーワード等なら何でもいいのですが、分かりやすいように次のような短いキーワードを使うことが慣例となっています)。
- shs
- sts
- scs
- cpc
- coc
- cic
- msm
- nen
- usu
- ici
- lvl
(出典:Kohya S.氏のツイート)
先ほどのくろくまちゃんの例なら上記のうち「usu」というキーワードをインスタンスプロンプトに割り当てています。
それからもう一つ、インスタンスプロンプトとセットで使う「クラスプロンプト」というものもあります。こちらは学習対象が何なのかを示すプロンプトで、くろくまちゃんの例なら彼はクマなのでクラスプロンプトは「bear」となります。
なぜ正則化画像が必要なのか?
以上を踏まえると、先ほどから挙げている例でいえばプロンプト「usu bear」は「くろくまちゃん風のクマ」を指すことになります。学習を行う際はこのプロンプトに「くろくまちゃん風のクマ」を関連付けるわけです。
しかし不都合なことにそのまま学習させると「usu」と「bear」という、プロンプトに含まれる両方の単語の概念が変わってしまいます。
一般的に言えばbearの概念は変えたくないので、正則化画像を使って「bear=クマ」と改めて学習させます。これによって「usu」だけに特定の絵柄を関連付けることができるというわけです。
ただし例外もある
ただし例えば
- bearの概念が変わっても気にしないよ
- 別にくろくまちゃんだけ出せればそれでいいからね
という場合もあると思います。その場合は正則化画像の必要性が薄まるので真面目に正則化画像をたくさん作る必要もないと思います。その辺は用途などに合わせて上手いこと考えて調整してください。
LoRAを使うための環境の構築方法(sd-scriptsを使用)
さて前置きが非常に長くなってしまいましたがここからが本題です。まずはLoRAを使うための環境の構築方法について丁寧に解説していきます。
なお、ここではKohya S.氏によるLoRA作成スクリプト「sd-scripts」のGUI版(Kohya’s GUI)を使わせて頂くことにします。詳しい導入方法は下記の公式ページに書いてあるのでそちらも併せてご覧頂きたいのですが…
分かりにくい部分も多いのでこの記事でも一つ一つ解説していきます。主な作業手順は次の3ステップです。
- PythonとGitをインストールしておく
- PowerShellでスクリプトを実行できるようにポリシーを変更する
- PowerShellでコマンドを打ち込み、環境を構築する
手順1:PythonとGitのインストール
まずはPythonとGitをインストールします。
Python
Pythonはプログラミング言語(とその実行環境)のパッケージです。今回ご紹介する方法では、執筆時点ではバージョン「3.10」が推奨されています(※それ以外だと上手く動かない場合があるようです)。ダウンロードページからインストーラーを選択してダウンロードし、インストールを行いましょう。

Git
Gitはプログラマの方にはお馴染みのバージョン管理ツールです。下記ページから最新版のインストーラーをダウンロードし、インストールしてください。

手順2:PowerShellでコマンドを実行できるようにポリシーを変更する
次に、この後の手順3で特定のコマンドを実行できるようにPowerShellの設定を変更します。一応書いておくとPowerShellは昔ながらの「コマンドプロンプト」のパワーアップ版で、スタートメニューで検索すると出てきます。
下記の手順を実行することはセキュリティ上のリスクを伴います。必ず自己責任で行ってください。
このPowerShellを右クリック→「管理者として実行」し、下記のコマンドを入力してください。
警告が出ますが、「Y」と入力してEnterを押しましょう。これで手順2は完了です。一旦PowerShellを閉じてください。
なお、一体何をやっているのかというとPowerShellの実行ポリシーを変更しています。詳しくは下記ページをご覧ください。

手順3:PowerShellでコマンドを打ち込み、環境を構築する
そうしたら今度はPowerShellを普通に開き、環境の構築作業を行います。次の11個のコマンドを一つずつ順番に入力していってください。なお下記はsd-scriptsのREADMEからの引用です。貼り付けミス等があるかもしれないので、必ずREADMEのほうもご確認ください。
- git clone https://github.com/bmaltais/kohya_ss.git
- cd kohya_ss
- python -m venv venv
- .\venv\Scripts\activate
- pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 –extra-index-url https://download.pytorch.org/whl/cu116
- pip install –use-pep517 –upgrade -r requirements.txt
- pip install -U -I –no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
- cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
- cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
- cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
- accelerate config
※3番目のコマンドを実行したとき、「Python」としか表示されない場合はコマンドの「python」を「py」に置き換えて再度実行してください。
最後のコマンドを実行すると、いくつか質問が出るので次の順番で回答しましょう。
- This machine
- No distributed training
- NO
- NO
- NO
- all
- fp16(※数字キーの「1」を押して選択)
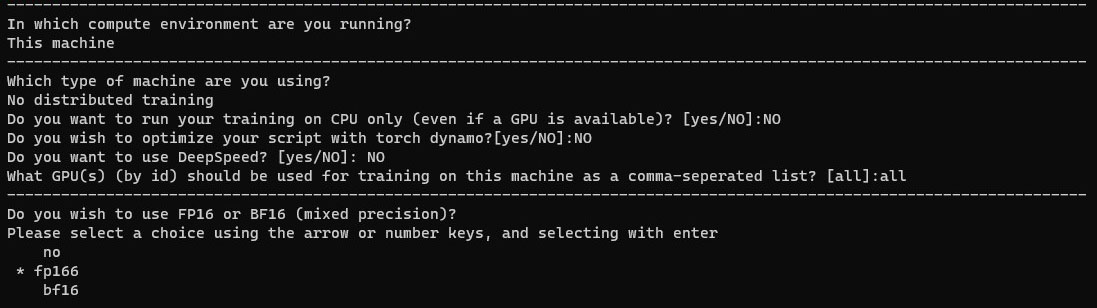
質問が表示されるので、この画像のように回答する
最後の7番目だけは、キーボードの数字キーで選択する必要があるので「1」を押してからEnterを押してください(矢印キーで選択すると強制終了するバグがあるそうです)。
お疲れさまでした。これで環境構築作業は完了です。
LoRAを使った学習のやり方
では次はいよいよLoRAを使って学習を行います。学習に必要な手順は次のとおりです。
- 教師データ等を準備する
- 「gui.ps1」を実行して設定を行う
- 学習を始める
手順1:教師データ等を準備する
教師データ
まずは教師データを準備します。先ほど説明した下記の要件を満たす質の高い画像をできるだけたくさん、できれば20枚以上は集めておきましょう。
- 学習させたい被写体が単体で映っている
- 画像ごとに被写体が色々なポーズをとっている
- 画像ごとに色々な背景が映っている
正則化画像
次に正則化画像は学習の元となるモデルを使って大量に生成した画像を使います。例えば先ほどのくろくまちゃんの例なら、Stable Diffusion v1.5を使って「bear」というクラスプロンプトのみで生成した画像が正則化画像となります(※ただし場合によってはクラスプロンプトだけだと質がかなり低い画像になることもあるので、その場合は別途用意したほうがいい場合もあります)。
枚数の目安はとりあえず「教師データの数×5枚」くらいでOKだと思います。まあもっとずっと多い方がいいという情報もありますが、お試しならこのくらいで十分でしょう。正則化画像をちゃんと用意したい場合は面倒ですが頑張って作ってください。
教師データ等のフォルダ構成について
最後に集めた画像を所定の名前のフォルダに入れます。フォルダ構成や命名規則は次のとおりです。
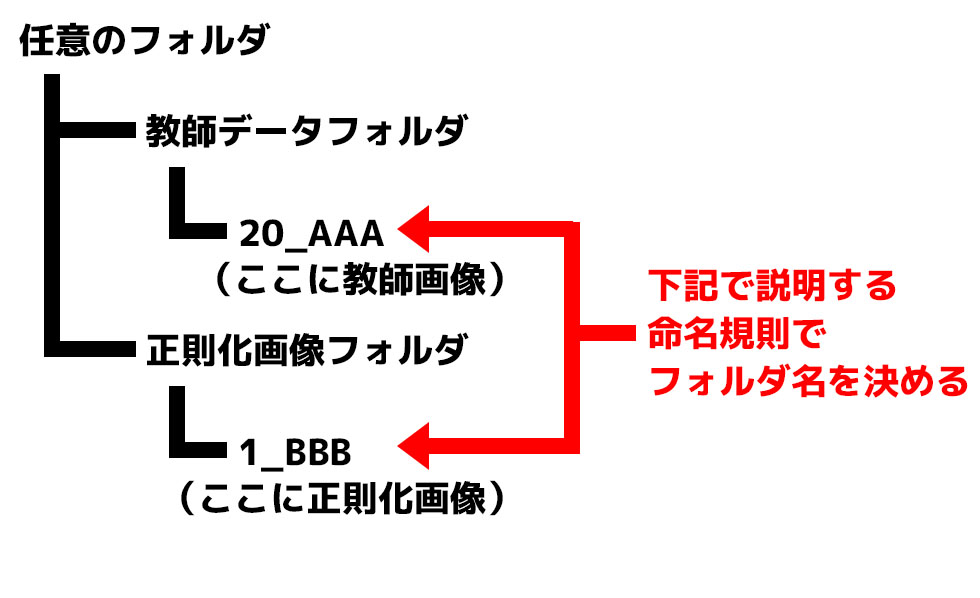
- 教師データフォルダ:「train」など任意の名前にする。
- 教師データとなる画像を入れるフォルダ:
「(繰り返し数)_(インスタンスプロンプト) (プロンプト)」という名前にする。
【例】インスタンスプロンプトが「usu」、プロンプトが「bear」で繰り返し数が20回ならフォルダ名は「20_usu bear」 - 正則化画像フォルダ:「reg」など任意の名前にする。
- 正則化画像を入れるフォルダ:
「(繰り返し数)_(プロンプト)」という名前にする。
【例】プロンプトが「bear」、繰り返し数が1回だけならフォルダ名は「1_bear」
これで学習の準備は完了です。
手順2:「gui.ps1」を実行して設定を行う
必要なデータを準備できたら、次はsd-scriptsの中にある「gui.ps1」を実行して設定を行います(ダブルクリックで実行できない場合は右クリック→「PowerShellで実行」を選択。もしくはバッチファイルのほうでもOKです)。
実行するとPowerShellが起動し、「Running on local URL:~」と出るので、URLの部分をCtrlを押しながらクリックしてください。するとブラウザが立ち上がって下のような画面になります。
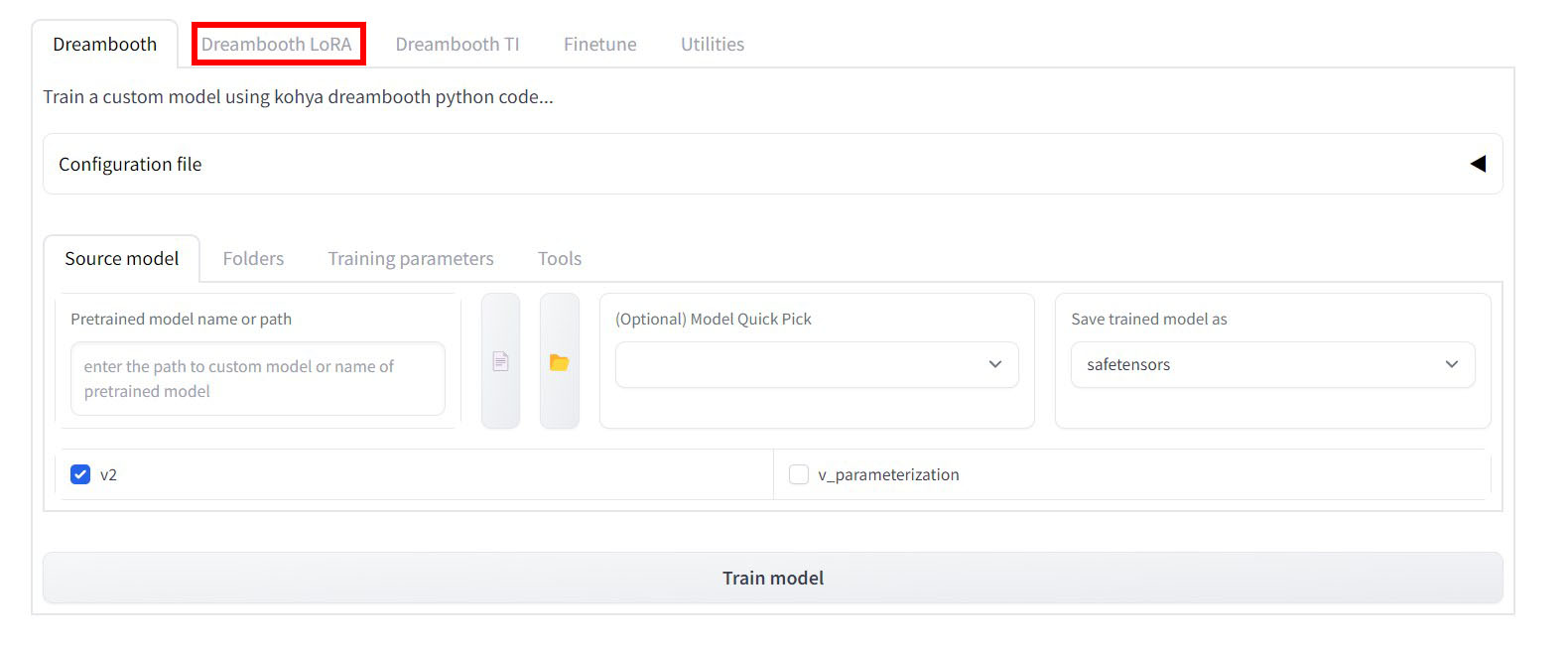
ここで「Dreambooth LoRA」タブを選択すると色々な設定項目が出現するので、次のタブごとに必要な設定を行っていきます。
- Source modelタブ
- Foldersタブ
- Training parametersタブ
Source modelタブ

元となるモデルファイルを指定するタブです。「Pretrained model name or path」にStable Diffusion系モデルのパスを入力しましょう(※モデルが手元にない場合はHugging Face等のサイトから予めダウンロードしておいてください)。
Foldersタブ

入出力先のフォルダ等を指定するタブです。次のように設定してください。
- Image folder:
先ほど出てきた「教師データフォルダ」に該当するフォルダを指定(子のフォルダを指定するわけではない点に注意) - Regularisation folder:
先ほど出てきた「正則化画像フォルダ」に該当するフォルダを指定(こちらも子のフォルダを指定するわけではない点に注意) - Output folder:出力先のフォルダを指定
- Model output name:出力するLoRAモデルの名前を入力
Training parametersタブ
学習に関する様々なパラメータがずらりと並んでいるタブです。色々な項目があって圧倒されてしまいますが、主に次の項目を設定します。
- Train batch size:
並列して行う学習の枚数。VRAM容量が10GB未満の場合は「1」にしてください。 - Epoch:
エポック数(=一つの訓練データを何回繰り返して学習させるか)。任意でOKで、お試しならとりあえず「10」くらいでいいと思います。 - Network Rank (Dimension):
学習の次元数。数値が大きいほど高精度な学習になるらしいです。単純な絵の場合は小さい値でも大丈夫でしょう。 - Network Alpha:
アルファ値。基本的には次元数と同じでOK。
このほかにも重要なパラメータがいくつかあるので、ぜひご自身で調べたり研究したりしてみてください。
手順3:学習を行う
ここまで設定が済んだらやっと学習処理を実行できます。GUI画面の一番下の「Train model」ボタンを押してください。ボタンを押してもGUI上には何も出ませんが、PowerShell上には処理内容が出るのでそちらを見ましょう。
しばらく待つと学習が完了し、LoRAモデルが出力されます。
「ページングファイルが小さすぎるため~」というエラーが出る場合
仮想メモリのサイズが足りていないときにこのエラーが出ます。学習にはかなりの量のメモリが必要で、普通のPCであればまず物理メモリが足りなくなるので仮想メモリも使用されます。ただその仮想メモリのサイズも小さいとメモリ不足になってしまうというわけですね。
このエラーの簡単な解決方法としては、システムで管理している仮想メモリのサイズを自分で変更して増やすやり方があります。詳しくはググって頂きたいのですが、ザックリした手順だけ書いておきます。
下記の操作は下手に行うとOSの動作に悪影響を与えかねないので、よく調べたうえで自己責任で行ってください。
- 「システムの詳細設定」を開く
- 詳細設定タブ→「仮想メモリ」の変更ボタンを押す
- 「すべてのドライブのページングファイルのサイズを自動的に管理する」のチェックを外す
- 仮想メモリを変更したいドライブを選び、「カスタムサイズ」を選択する
- 初期サイズ・最大サイズに、割り当てたい仮想メモリのサイズを入力する
- 必ず「設定」ボタンを押す(※押さないと設定が反映されません)
- OKボタンを押し、PCを再起動する
具体的に仮想メモリがどれくらいあればよいのか?という点はお使いのPCの性能にもよるため一概には言えませんが、物理メモリと合わせて80GBくらいのサイズがあれば問題なく学習できるらしいです。参考になさってください。
LoRAモデルを使って画像を生成する方法(Stable Diffusion web UIが必要)
最後に、LoRAモデルを使って画像を生成する方法について解説します。
前提:Stable Diffusion web UIの導入
まず、ここでご紹介する方法ではAUTOMATIC1111氏の「Stable Diffusion web UI」を使います。「まだインストールしてないよ」という方は下記の記事を参考にして導入を済ませておいてください。

LoRAモデルを所定のフォルダに移動させる
次に、LoRAで作ったモデルをweb UIの所定のフォルダに移動させます。移動先は下記のとおりです。
移動させたらweb UIを起動させましょう。
LoRAモデルの使い方
LoRAモデルを使うには、プロンプトにLoRAモデルを使うことを明記する必要があります。ただ自分で入力するのは面倒くさいので簡単に入力できる方法をご紹介します。
まず、下の画像の花札(?)アイコンを押します。
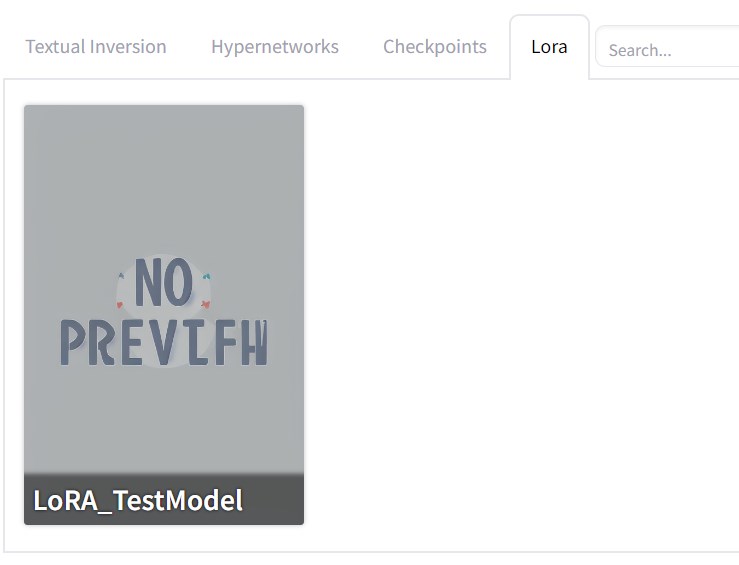
すると下のようなタブ付きの項目が出るので、「Lora」タブを押して出てきたモデルを選択します。
そうするとプロンプト欄に
というようなプロンプトが入力されます。モデル名の後の数値(上記の例では1)はLoRAモデルの適用度です。1のままだと絵柄がかなり強く出るので、必要に応じて値を減らすなど上手く調整してください。
これでLoRAモデルが適用されるようになります。上の方で決めたインスタンスプロンプトも忘れずに書いてから画像を生成しましょう。
おわりに
以上、かなり長くなってしまいましたがLoRAを使った学習のやり方について一通り解説しました。
執筆時点では準備が大変なので圧倒されてしまう方も多いかと思いますが、LoRAは苦労に見合うだけの強力な学習手法なのでぜひ一度頑張ってお試しいただければと思います。
この記事が何かしら参考になれば幸いです。

