
今回もStable DiffusionのControlNetに関する話題で、タイトルのとおり
を一通りまとめて比較してみるという内容になっています。
ControlNet 1.1ではプリプロセッサの数が大幅に増えたのですが、便利になった反面
- 種類が多すぎてどれを使えばいいのかよくわからんな…
- このプリプロセッサは他のやつどどう違うんだろう??
と混乱してしまいますよね。
そこでここではControlNet 1.1のプリプロセッサについて、それぞれ何が違うのか?といった点を解説していきますね。
前提:ControlNetのプリプロセッサとは?
まずはじめに予備知識的な話なのですが、ControlNetのプリプロセッサとは一言でいえば
を指します。例えば入力画像の輪郭を抽出して画像を生成する「Canny」モデルのプリプロセッサでは、前処理として下記のように輪郭の抽出を行います。
| 入力画像 | プリプロセッサの出力 |
|---|---|
 |
 |
このようにプリプロセッサでは、各モデルが活用しやすい形になるように入力画像を加工する役割を持っています。
モデルごとのプリプロセッサの比較まとめ
ではモデルごとのプリプロセッサの比較をしていこうと思います。なお今回は複数あるプリプロセッサの比較が目的なので、ここでは対応するプリプロセッサが一つしかないモデルに関しては解説を省略します。つまり下記の7つのモデルを取り上げて解説しますね。
- Lineart
- Depth
- Normal
- Scribble
- Soft Edge
- Segmentation
- Openpose
ちなみに比較の際の条件は、特に記載がない場合下記のとおりにするものとします。
Lineart
入力画像を線画に変換し、それを元に画像生成を行うモデルです。
入力画像
| プリプロセッサの種類 | プリプロセッサの出力 | 生成したイラストの例 |
|---|---|---|
| lineart_coarse |  |
 |
| lineart_realistic |  |
 |
| lineart_standard |  |
 |
プリプロセッサの出力結果を見てみるとそれぞれ結構違いがありますね。
- coarseはその名の通り粗い感じ
- realisticは一番精細
- standardは上2つの中間
といった感じでしょうか。ただ生成したイラストを見るとどれがいいかは好みによると思うので、好きなものを使っていただいてOKでしょう。
Depth
入力画像の深度情報を元に画像生成を行うモデルです。プリプロセッサでは深度の推定を行います。
入力画像
| プリプロセッサの種類 | プリプロセッサの出力 | 生成したイラストの例 |
|---|---|---|
| depth_leres |  |
 |
| depth_midas |  |
 |
| depth_zoe |  |
 |
プリプロセッサの出力を見るとzoeが一番きれいな深度マップを生成できているので、使うならzoeが一番オススメです。
Normal
入力画像の法線情報を元に画像生成を行うモデルです。プリプロセッサでは法線マップを生成します。
入力画像
| プリプロセッサの種類 | プリプロセッサの出力 | 生成したイラストの例 |
|---|---|---|
| normal_bae |  |
 |
| normal_midas |  |
 |
midasが変な法線マップを出力する一方で、baeは正しい法線マップを出力できています。Normalモデルを使うときはbaeのほうを使いましょう。
Scribble
落書きを清書するモデルです。

入力画像
| プリプロセッサの種類 | プリプロセッサの出力 | 生成したイラストの例 |
|---|---|---|
| scribble_hed |  |
 |
| scribble_pidinet |  |
 |
| scribble_xdog |  |
 |
プリプロセッサの出力を見るとまあまあ違いがありますね。でもイラストの生成結果は一概に「これがいい!」という感じでもなく好みによると思うので、好きなものを使っていただいてOKだと思います。
Soft Edge
柔らかい輪郭線を生成し、それを元に画像を生成するモデルです。
入力画像
| プリプロセッサの種類 | プリプロセッサの出力 | 生成したイラストの例 |
|---|---|---|
| softedge_hed |  |
 |
| softedge_hedsafe |  |
 |
| softedge_pidinet |  |
 |
| softedge_pidisafe | 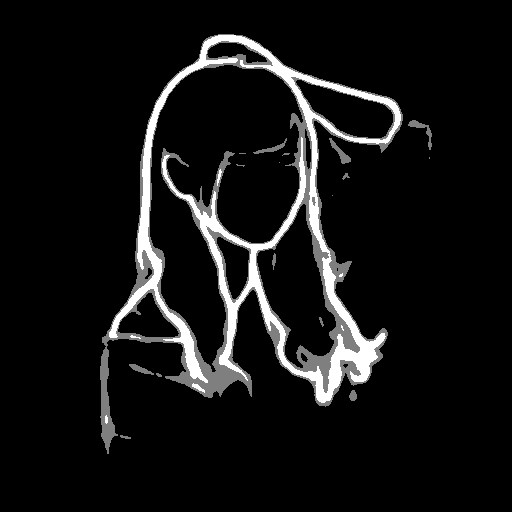 |
 |
ControlNet 1.1で
- softedge_hedsafe
- softedge_pidisafe
という2つの新しいプリプロセッサが追加されました。このプリプロセッサが追加された理由は、公式ドキュメントによると
HED または PIDI がソフト推定内の元の画像の破損したグレースケール バージョンを隠す傾向があり、そのような隠されたパターンが ControlNet の注意をそらし、悪い結果につながる可能性があるという事実が原因です。(※機械翻訳)
とのこと。まあ要するに従来のプリプロセッサの処理だとControlNet側の処理が上手くいかない場合があるので、その対策を講じたのが上記2つのプリプロセッサだそうです。
Segmentation
セマンティックセグメンテーションという手法で入力画像の物体を認識し、分割を行ってそれを元に画像を生成するモデルです。

入力画像(出典:ぱくたそ 様 https://www.pakutaso.com/)
| プリプロセッサの種類 | プリプロセッサの出力 | 生成したイラストの例 |
|---|---|---|
| seg_ofade20k |  |
 |
| seg_ofcoco | 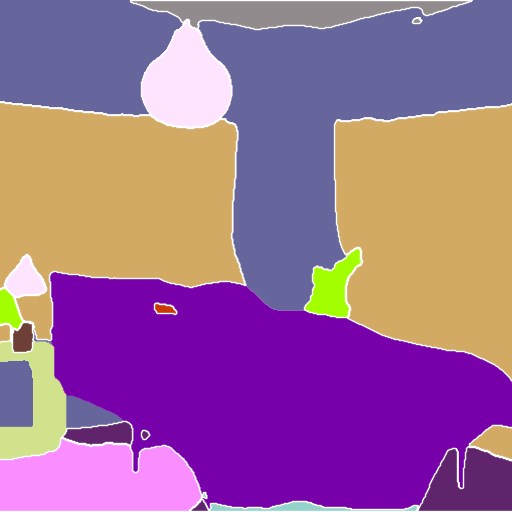 |
 |
| seg_ufade20k |  |
 |
プリプロセッサの出力を見てみるとそれぞれ違うことが分かりますが、生成したイラストを見ると甲乙つけがたい感じなので好きなものを使っていただいてOKだと思います。
Openpose
入力画像の人物のポーズを認識して棒人間画像を作成し、それを元に画像生成を行う人気のモデルです。

入力画像(出典:ぱくたそ 様 https://www.pakutaso.com/)
| プリプロセッサの種類 | プリプロセッサの出力 | 生成したイラストの例 |
|---|---|---|
| openpose | 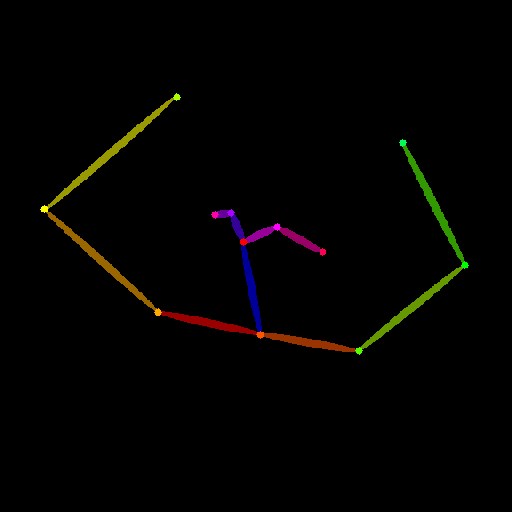 |
 |
| openpose_face | 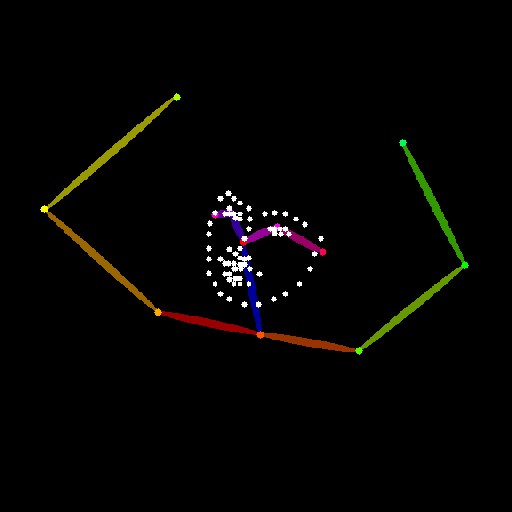 |
 |
| openpose_faceonly |  |
 |
| openpose_full |  |
 |
| openpose_hand | 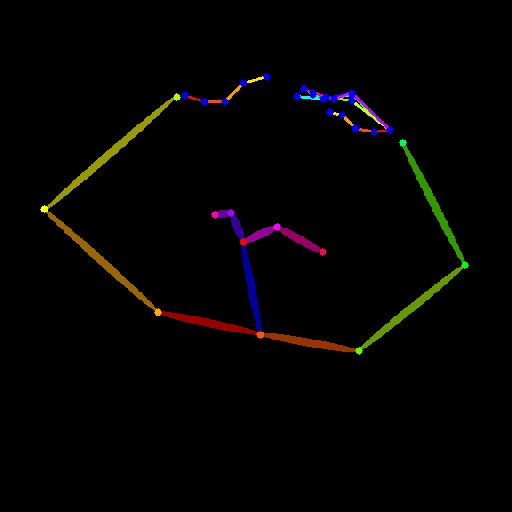 |
 |
ControlNet 1.1では手や表情を認識するためのプリプロセッサが追加されて
- openpose:棒人間だけ(手や表情は無し)
- openpose_face:表情と棒人間(手は無し)
- openpose_faceonly:表情だけ
- openpose_full:表情と手のついた棒人間のフルセット
- openpose_hand:手のついた棒人間(表情は無し)
の5種類になりました。用途によって使い分けるのがよいと思いますが、基本的には
- openpose
- openpose_full
のどちらかのプリプロセッサを使えば十分でしょう。
おわりに
以上、ControlNet 1.1の各プリプロセッサの特徴や比較結果について解説しました。選択したプリプロセッサによって結果が結構違ってくる場合があるので、適当に選ぶのではなくぜひ用途に合わせたプリプロセッサを選択していただければと思います。
この記事が何かしら参考になれば幸いです。

