
今回はStable Diffusionの基礎に関する話題で、タイトルの通り
をなるべくわかりやすく解説するという内容になっています。
私はStable Diffusionを使い始めて9か月くらいになりますが、恥ずかしながらその仕組みについては何とな~く知っていた程度で詳しいことはよく分かりませんでした。しかし最近になって「画像生成AIについて色々書いているのに根本的な仕組みを知らないんじゃちょっと恥ずかしいよな」と思い、今更ではありますが少し真面目に勉強することにしました。
このような次第で色々な文献を読み漁り、多少は仕組みを理解できた…つもりなのでここではその辺の知識をできるだけ簡潔に書いてみようと思います。
おそらくStable Diffusionをお使いの方の多くは
- いつも画像を生成しているけど、結局どういう仕組みなんだろう?
- 一応調べてみたものの難しくてよく分からん…
という感じかなと思いますので、この機会にぜひご覧いただき「へ~、そうなんだな」程度に思って頂ければ幸いです。
私はAIの専門家でないばかりか全くの素人であり誤解している部分があるかもしれません。最後に参考文献の一覧を掲載しておきますので、確実な情報を知りたい方は必ずそちらもご確認ください。
(もし間違っている箇所があったらコッソリ教えてください…)
Stable Diffusionの画像生成の仕組み・処理の流れ
でははじめに、Stable Diffusionの大まかな仕組みや処理の流れについて解説します。文章だけで説明するとかなりわかりづらいので、ここではまず画像生成処理の流れを簡単に示した図を掲載します。
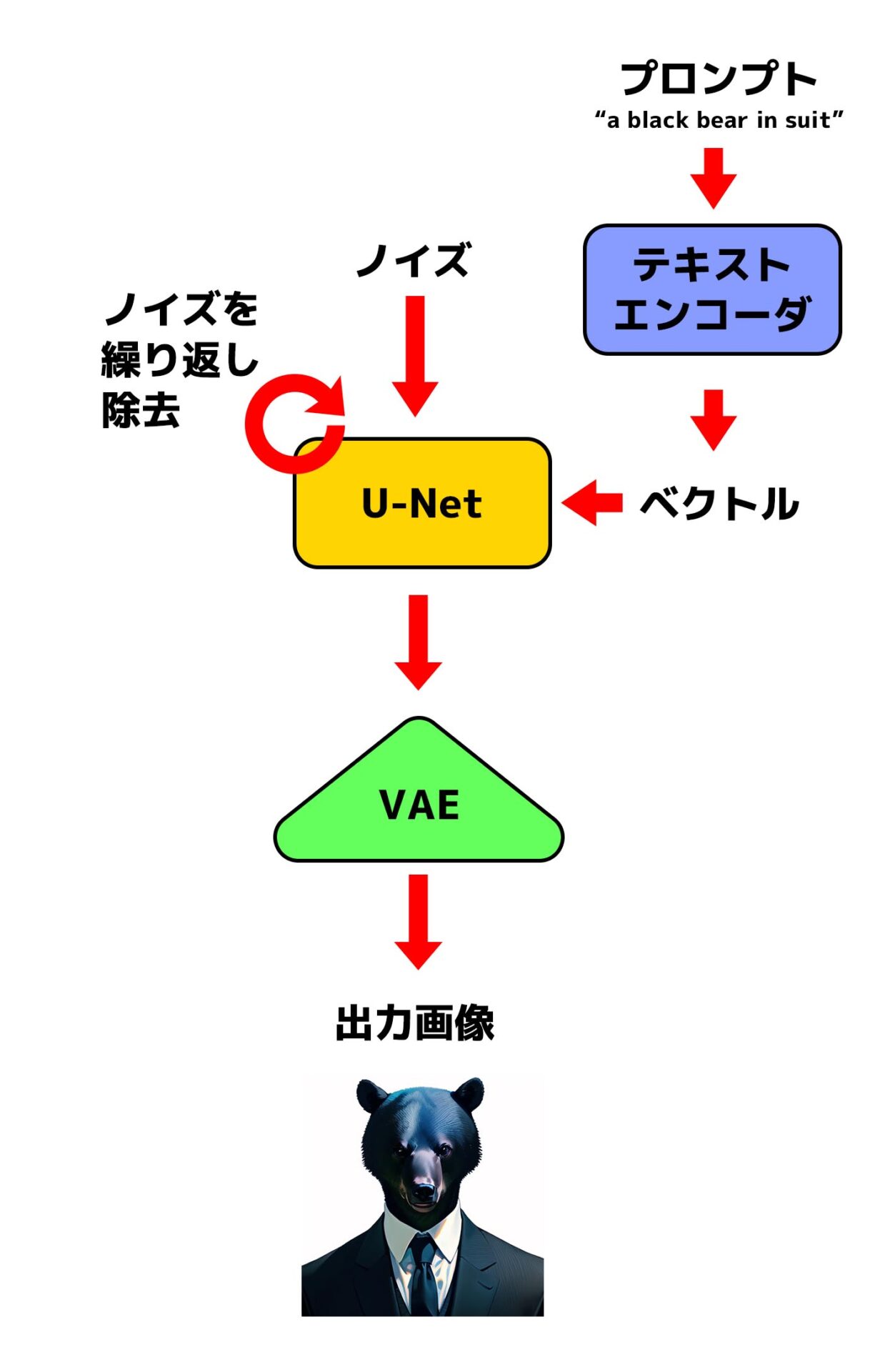
Stable Diffusionの処理の流れ。HuggingFaceの記事(https://huggingface.co/blog/stable_diffusion)を参考にわかりやすく簡略化したもの。
改めて処理の流れを書き起こすと次のようになります。
- ノイズとプロンプト(呪文)をそれぞれ入力として受け取る。ノイズは「U-Net」と呼ばれる画像生成器へ、プロンプトはテキストエンコーダへ送られる。
- テキストエンコーダがプロンプトをベクトルに変換する。
- 変換されたベクトルを参考にしつつU-Netがノイズを除去していく。この作業を何回か繰り返す。
- ノイズ除去後は、(ノイズだったものが)VAEによって高解像度の画像に変換されて出力される。
具体的な用語については後ほど解説します。とりあえずStable Diffusionによる画像生成のポイントはノイズを除去していくという点にあるのでまずはそれを押さえてください。
ノイズを除去してきれいな画像にする「拡散モデル」について
さて画像生成AIに関するありがちな誤解として
というものがあります(※だから著作権侵害だなどと、たまにアンチAI派の人が無茶苦茶な主張をしているのを見かけますよね)。しかし当然ながらStable Diffusionではそんなローテクで非効率的なことをしているわけではありません。
じゃあ一体どうやって画像を生成しているのかというと、Stable Diffusionは
ような処理を習得しています(このような学習を行ったモデルを拡散モデルといいます)。
…ただこれだけだと「そんなのどうやるのさ?」と疑問に思うので、まずは逆のこと・すなわち画像にノイズを加えることを考えてみます。画像編集ソフトを使ったことがある方ならすぐにわかると思いますが画像にノイズを加えるのは簡単です。

そこで画像にノイズを徐々に加えて最終的に完全なノイズにすることにしましょう。するとその過程で
ということが分かってきます。これを利用して十分に学習を進めれば、ある時点において「前のステップでこの画像にどれだけのノイズが追加されたか?」を予測できるようになります。ここでのポイントはノイズの追加量を予測するという点です。
そうしたら次は先ほどの過程を逆に遡ることを考えます。つまり
と予測するわけです。先ほどの「元画像→ノイズ画像」という過程でノイズの追加量を予測できるならその逆の予測も可能になります。そしてどれだけノイズが加えられたか?という差分がわかれば、それをノイズ画像から差し引くことでノイズを除去していくことが可能です。
拡散モデルではこのような予測によってノイズからきれいな画像を生成することができます。ちなみになんでわざわざこんな方法を採用しているのかというと、他の方法と比較していくつかメリットがあるからです。例えば
- 多様性のある画像を生成できる
- 安定して学習を行わせることができる
- 条件付けで生成を制御することができる
といった点は大きな特徴でしょう。
拡散モデルの高速化手法
ただし拡散モデルにも弱点があります。それは学習や生成に時間がかかることです。
そこで様々な高速化手法が考案されています。Stable Diffusionの場合は画像をそのまま扱うのではなく、まずは潜在空間とよばれるコンパクトな表現空間の中でノイズを処理していきます。
潜在空間とはAIが学習した「データの特徴やパターン」を把握するための数学的な表現空間です。この空間内ではデータの特徴がコンパクトで意味のある数学的表現(=潜在表現)に変換されており、データの可視化や特徴抽出が容易になります。
このような手法を使うことで拡散モデルが扱うデータのサイズは数十分の一にまで削減され、処理が大幅に高速化されます。ただしそのままでは画像として出力できないので、最終的には後述するVAEによって潜在表現から画像データに変換する必要があります。
どうやってテキストから画像を生成するの?
さて先ほどまでの説明では画像生成に焦点を当ててご説明しましたが、まだ入力したテキストからその通りの画像を生成する方法が分かりません。そこでこの点について簡単にご説明します。
まず入力したテキストから目的の画像を得るためには、そのテキストと生成中の画像がどの程度類似しているか?を知る必要があります。そこで登場するのがテキストエンコーダです。
テキストエンコーダでは入力されたプロンプトを、拡散モデルが扱いやすいベクトル(≒数字の列)に変換します。ここでStable Diffusionが採用しているテキストエンコーダには予め
- このプロンプトはこういう意味で、多分こういう画像を表しているんだな
- それならこのプロンプトをこういうベクトルに変換すればいいだろう
ということを学習させてあるので、テキストエンコーダはプロンプトを適切なベクトルに変換することができます。
ここまできたらあとはこの情報を参考にして画像生成器が画像を生成します。ザックリ言うと潜在表現にプロンプト由来の情報を条件付けして「今よりさらにプロンプトに近い画像」の生成を行います。これによってプロンプト通りの画像が生成されるというわけです。
Stable Diffusionを構成する3つの技術
ここまで大まかな処理の流れについてご理解頂いたところで、次は少しだけ踏み込んでStable Diffusionを構成する技術をごく簡単にご紹介しようと思います。この技術としては主に次の3つが挙げられます。
- VAE
- U-Net
- テキストエンコーダ
それぞれザックリ見ていきましょう。
VAE
VAE(Variational Auto-Encoder、変分オートエンコーダ)はStable Diffusionの高速化を支えているニューラルネットワークです。上の方でもご説明した通り拡散モデルで高解像度の画像を生成しようとすると計算量が多くなってしまうのですが、VAEを使うことで処理の効率化を図ることができます。
具体的には画像生成においてはVAEは
処理を担います。潜在空間の中でノイズが乗った潜在表現からノイズを除去する処理を行い、後でそれをVAEによって高解像度の画像に変換することで計算量を大幅に削減しています。
U-Net
次にU-Netは画像生成の中核をなす部分で、ノイズの除去工程を担うニューラルネットワークです。下図のように概念図がアルファベットのUの字のような形状をしているので「U-Net」と呼ばれているそうです。
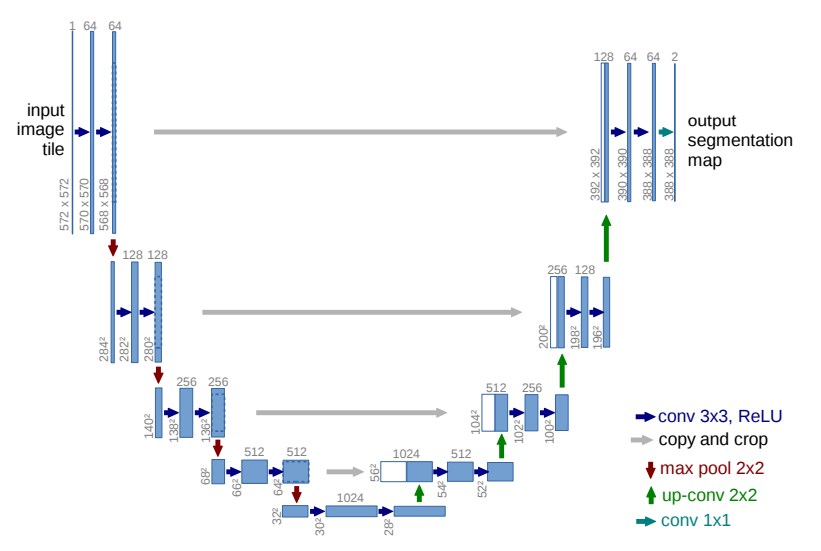
出典:https://arxiv.org/abs/1505.04597 ※Stable Diffusionで使われているU-Netはこれの改造版。
U-Netは元々は「画面に配置されたオブジェクトが何なのかを判別する」ための技術として生まれました。しかしStable Diffusionではこれを改造して画像生成に利用しています。
U-Netの詳細については参考文献の論文等をご覧ください。残念ながら私の脳みそでは簡潔にご説明できそうにありません…。
テキストエンコーダ
最後にテキストエンコーダは、(先ほども少しご説明した通り)Stable Diffusionではプロンプトをベクトルに変換するための仕組みとして使われています。Stable Diffusionではバージョンごとに下記のテキストエンコーダが使われています。
- Stable Diffusion v1:CLIP
- Stable Diffsuion v2:OpenCLIP
CLIPとはOpenAIが開発した画像を分類するためのモデルです。CLIPの特徴は画像とテキストの情報を対照的に学習するという点です。これによってモデルは画像とテキストの関連性を理解し、画像の内容をテキストで表現したりテキストから画像を予測したりすることが可能になっています。
参考文献






おわりに
以上、すごく今更な感じはありますがStable Diffusionの仕組みについてなるべくわかりやすくご説明しました。
もちろん仕組みを知らなくても画像は生成できますから「難しいのはちょっと…」という方は無理をすることもないと思います。しかしその辺を知っていると画像生成に対する理解が更に深まりますし何より面白いので、この記事の内容で満足せずにぜひ上記の参考文献などもご覧いただければと思います。
いずれにしてもこの記事が何かしらお役に立てば幸いです。

