
今回は音声生成AIに関する話題でタイトルのとおり
日本語音声生成AI「Irodori-TTS」の導入方法・使い方
をわかりやすく・丁寧にご紹介するという内容になっております。
ローカル環境で使える日本語の音声生成AIというと「Style-Bert-VITS2」などがありましたが、最近になって新しい日本語音声AI「Irodori-TTS」が登場し少し前に一部界隈で話題になったようです。
ここではこのIrodori-TTSについて、ローカル環境への導入方法などを解説していきますね。
Irodori-TTSについて
公式リポジトリ
「Irodori-TTS」とは?
Irodori-TTSはAratako氏が開発している「テキストから音声を生成」(=Text to Speech、略してTTS)するタイプのAIです。主な特徴は次のとおり。
- 自然な日本語音声を生成
- 絵文字を使って音声の感情を制御可能
- 参照音声を使った声の複製機能あり
- 声の性別や質をキャプションを使って指定可能
- 誰でも無料で利用可能
一番面白い特徴はやはり「絵文字による感情制御」でしょう。音声生成時にテキストに絵文字を含めるとその絵文字に合ったボイスを生成してくれます。
サンプルボイス
では私がIrodori-TTSを使って実際に生成したサンプルボイスを試しに聞いていただこうと思います。
サンプルボイス1:くろくまの自己紹介(オーソドックスな読み上げ)
テキスト:
こんにちは。「くろくま」と申します。私は「くろくまそふと」という技術ブログを運営しており、画像生成AIやゲーム開発に関する記事を書いています。よろしくお願いいたします。参照音声:なし
生成した音声:
サンプルボイス2:ほしいものが届いてめちゃくちゃ喜んでいる女の子
テキスト:
うわあああ✨ついに、ついに届いたよ!📦💖 ずっとずっと待ってたんだから!見てこの輝き、最高すぎて語彙力ゼロになりそう🌈😭参照音声(「こういう声で生成して」と指定するための音声):
生成した音声:
サンプルボイス3:部屋に恐ろしい何かが住んでいることに気付いた女の子
テキスト:
ねえ、ちょっと待って……😱 部屋の隅に、誰か……いる?👤 暗くてよく見えないけど、こっちをじっと見てる気がする……💦 やだ、怖い、動けない!誰か助けて😨 ひっ、今、目が合った気がする……!!👁️💀参照音声:(サンプル2と同じ)
生成した音声:
Irodori-TTSの導入方法
次に、ここからが本題でIrodori-TTSの導入方法をわかりやすく解説していきます。主な手順は次のとおり。
- Gitとuvをインストールする
- Irodori-TTSの公式リポジトリをクローンする
- uv syncコマンドを実行する
それぞれ詳しく見ていきましょう。
手順1:Gitとuvをインストールする
まず、バージョン管理ツールの「Git」とパッケージ管理ツールの「uv」をインストールしておく必要があります。
Gitのインストール方法
Gitはバージョン管理ツールです。…まさかこのブログをご覧になるような方でまだGitをインストールしてない方はいないでしょうけど、もし「いやまだだぜ!」という方がいたら下記の公式サイトからインストーラをダウンロードしてインストールしておきましょう。

uvのインストール方法
次にuvは次世代のパッケージ管理ツールで、主にPython環境の整備や管理を行ってくれる便利なやつです。
uvのインストール方法に関しては公式ページをご覧いただきたいのですが、ザックリ書くとPowershellを管理者権限で開いて下記のコマンドを実行すればOKです。
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"手順2:Irodori-TTSの公式リポジトリをクローンする
次にGitのコマンドを使ってIrodori-TTSの公式リポジトリをクローン(=複製)します。Irodori-TTSを導入したいフォルダを右クリック→「ターミナルで開く」を選択すると黒い画面が出るので、次のコマンドを入力して実行してください。
git clone https://github.com/Aratako/Irodori-TTS.git手順3:uv syncコマンドを実行する
そうしたらIrodori-TTSフォルダに移動してから「uv sync」コマンドを実行します。まず、↑のコマンドを実行後に作成されるフォルダに移動します。
cd Irodori-TTS次に「uv sync」コマンドを実行してIrodori-TTSの実行に必要なものを自動的にインストールしましょう。
uv syncこれでセットアップ完了です!
Irodori-TTSの基本的な使い方
では次にIrodori-TTSの基本的な使い方をご説明します。Irodori-TTSはコマンドライン上で音声生成を行う方法とWebUIを使って音声生成する方法の2通りがあるのですが、ここでは簡単なWebUIを使う方法を解説しますね。
WebUIの起動方法
WebUIを起動するには、Irodori-TTSのインストールフォルダを右クリック→「ターミナルで開く」を選択して下記のコマンドを実行します。
uv run python gradio_app.py --server-name 0.0.0.0 --server-port 7860次にブラウザを開いて下記のURLにアクセスしてください。
http://localhost:7860下のような画面が出れば起動成功です。
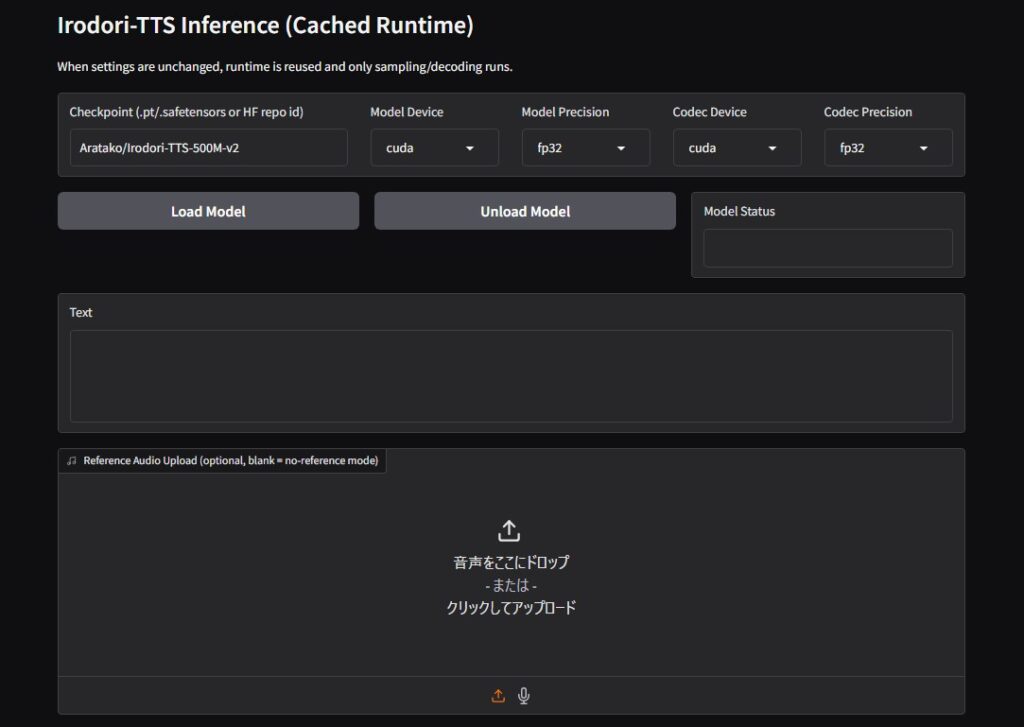
モデルのロード
さて音声を生成する前に音声モデルを読み込む必要があります。とりあえずデフォルトのモデルを読み込むには、「Checkpoint」と書かれているところの下の欄が「Aratako/Irodori-TTS-500M-v2」となっていることを確認してから「Load Model」ボタンを押します。
初回ロード時は1.8GB程度あるモデルをダウンロードするので、読み込みが完了するまでにはしばらく時間がかかります(2回目以降は少し待つだけで読み込めます)。
音声生成のやり方
参照音声なしの場合
まず参照音声を使わない場合は「Text」欄に生成したいセリフを書いて「Generate」ボタンを押すだけです。Irodori-TTSの音声生成は比較的高速で、グラフィックボードを搭載したPCであれば100文字程度のセリフのボイスは10秒もかからずに生成されます。
なお参照音声なしの場合は、生成されるボイスの性別や質などはランダムになるようです。
参照音声を使う場合
既にある音声(例えば自分の声のデータとか)を参照音声として使うと、その音声そっくりの新しいボイスを生成することができます。やり方は簡単で「Reference Audio Upload」欄(「音声をここにドロップ」と書かれている部分)に参照音声をドラッグ&ドロップしてから音声生成を行うだけです。
VoiceDesignを使って声の性別や質を指定する方法
さて上記は普通にテキストから音声を生成する方法ですが、音声生成の際に声の性別や声質などを指定したくなる場面も多いですよね。このような場合はVoiceDesign機能を使うとキャプションを使ってそれらを指定できます。
VoiceDesign版のWebUIの起動方法
VoiceDesignは先ほどの通常版とは別のWebUIを使う必要があるので、下記のコマンドを実行します。
uv run python gradio_app_voicedesign.py --server-name 0.0.0.0 --server-port 7861そうしたら下のURLをブラウザで開きましょう。
http://localhost:7861するとパッと見は通常版と同じですがよく見ると少し違うWebUIが起動します。
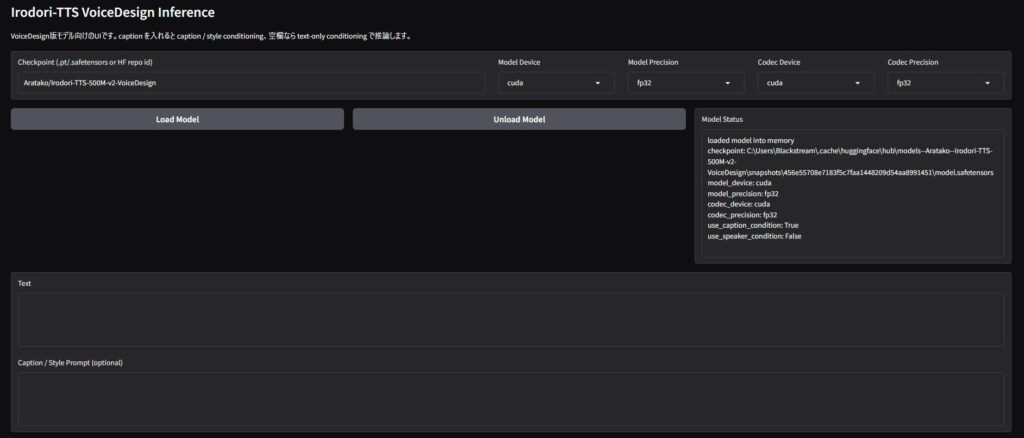
VoiceDesign版の音声生成のやり方
あとは通常版と同様にモデルをロードして音声生成を行えばOKです。モデルは通常版とは別なので、初回ロード時はダウンロード処理が走ります。しばらく待ちましょう。
ロードが完了したら「Text」欄にセリフを入れるのですが、その下の「Caption / Style Prompt」欄には欲しい声の性別や声質を説明するプロンプトを入れましょう。例えば
Text:
おーほっほっほっ! まさかこれほど素晴らしい趣向が用意されているなんて、わたくし、感動いたしましたわ!
Caption / Style Prompt:
高飛車なお嬢様のような、若い女性話者と入れると次のような「高飛車なお嬢様のような女性のボイス」が生成されます。
おわりに
以上、Irodori-TTSの導入方法や使い方について解説しました。自然な日本語ボイスを生成でき、絵文字で簡単に感情を制御できて便利なので色々活用できそうですね。皆さんもこの機会にぜひ試してみてください。
この記事が音声生成のお役に立てば幸いです。

